mpd² Year 1 Cohort — Northwestern University, 2026
Year One Reflection
From Technical Launch Owner to Product-System Strategist
I came into mpd² as an engineer who knew how to launch things. Six years of NPI at Stryker taught me that if you get the process right — PPAP, supplier readiness, tooling, validation — the product ships. What I couldn't always do was explain why this product over another, or why now instead of next quarter, in language that moved a room.
Year one changed the altitude. Not reinvention — expansion. I still bridge R&D and Manufacturing. I still launch things. But now I can frame the opportunity upstream, defend it financially, ground it in evidence, and carry people along through the decision.
Project Highlights
ReCleat
Product Design
Built a full business case for a modular shoe upper — market sizing, supply-chain economics, sustainability impact, and executive pitch
Athleta Wellbeing System
Design Understanding
Designed a physical-digital wellbeing concept from ethnographic insight through phased rollout with business logic
Shift-Knob Redesign
Sustainability
Took a sustainability redesign from ambitious claims to defensible LCA — PP, recycled aluminum, die casting, regrind loops
Golf-Ball LCA
Sustainability
Reframed environmental impact around functional unit, retrieval infrastructure, toxicity, and user behavior
Energy Gel Launch
Finance
NPV model with sensitivity analysis, cannibalization logic, and capacity/CapEx timing ending in a go/no-go recommendation
XmR / Cpk Launch Deck
Data Analytics
Translated process capability into a launch-timing recommendation for leadership using control limits and exceedance rate
Full-Factorial DOE
Data Analytics
Power estimation, screening, interaction modeling, and recipe-based optimization for a manufacturing process
ALKO Inventory Synthesis
Supply Chains
Compared total cost and marginal ROI by SKU class, showing how correlation erases pooling benefits
Beer Game Debrief
Supply Chains
Made bullwhip distortion visceral — demand signaling, information sharing, lead-time amplification, MOQ effects
China CM Negotiation
Negotiation
Turned a binary supplier approval fight into tiered options using objective criteria and BATNA
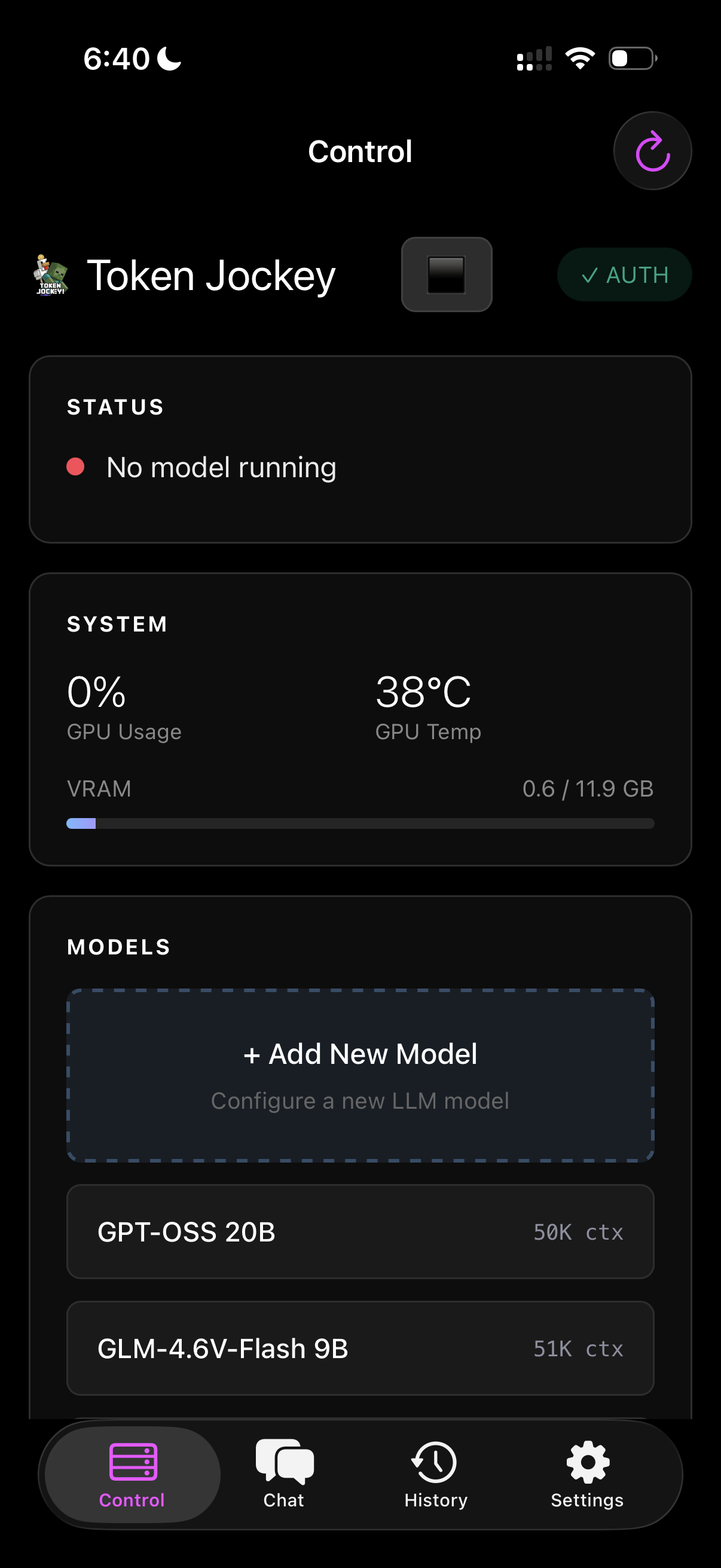
The AI Thread
What started as curiosity about local LLMs in December became Token Jockey, then LLM Launcher, then Chi-Muter — each one a step from tinkering toward building real product systems with specs, evals, and users in mind. AI Jetpacks formalized the shift: from using chat tools to designing prompts, retrieval pipelines, evals, and repeatable workflows as infrastructure around real work.
Eleven Courses, Three Quarters
- 01Fall '25 Introduction to Product Design & DevelopmentWill & Marty
- 02Fall '25 Effective CommunicationBeth Bennett
- 03Fall '25 Sustainability in the Product Development ProcessCraig Arnold
- 04Fall '25 Team Building & Organizational BehaviorCaroline Marie Vial
- 05Winter '26 Accounting Issues for Product DevelopmentRobin Soffer
- 06Winter '26 Understanding through DesignGreg Holderfield
- 07Winter '26 Financial Issues for Product DevelopmentLeonardo Brubaker
- 08Winter '26 Negotiation / Conflict ResolutionConnie Meyer
- 09Spring '26 Leading with Data AnalyticsTony Orzechowski
- 10Spring '26 Global Product Design & Supply ChainsAchal Bassamboo
- 11Spring '26 Product ManagementBirju Shah & Jason Beauregard
That's what Year Two is for — doing it for real, at a higher altitude, with sharper wedges.